Loading Data via Zarr Endpoints¶
Zarr Format Benefits:
- Scalable, flexible
- Easy to access via HTTP/HTTPS in cloud storage
But:
- Majority of datasets in HDF5 (netCDF4)
- HDF5/netCDF4 hard to access via HTTP/HTTPS in cloud storage
Freva Solution:
- REST API streams any file format as Zarr
- Zarr protocol endpoints accessible via any Zarr library
Workflow¶
- Search netCDF4 datasets using Freva-REST API
- Access data through Zarr endpoints
Let's define the search parameters for the Freva-REST API and import what we need
search_params = {"dataset": "cmip6-fs", "project": "cmip6"} # Define our search parameters
url = "http://localhost:7777" # URL of our test server.
from getpass import getpass
import requests
from tempfile import NamedTemporaryFile
import xarray as xr
If we normally search for data we will get the locations of the netCDF files on the hard-drive:
list(requests.get(
f"{url}/api/databrowser/data_search/freva/file",
params=search_params,
stream=True
).iter_lines(decode_unicode=True))
['/home/wilfred/workspace/freva-nextgen/freva-rest/src/databrowser_api/mock/data/model/global/cmip6/CMIP6/CMIP/MPI-M/MPI-ESM1-2-LR/amip/r2i1p1f1/Amon/ua/gn/v20190815/ua_mon_MPI-ESM1-2-LR_amip_r2i1p1f1_gn_197901-199812.nc', '/home/wilfred/workspace/freva-nextgen/freva-rest/src/databrowser_api/mock/data/model/global/cmip6/CMIP6/CMIP/CSIRO-ARCCSS/ACCESS-CM2/amip/r1i1p1f1/Amon/ua/gn/v20201108/ua_Amon_ACCESS-CM2_amip_r1i1p1f1_gn_197901-201412.nc']
What if the data location is not directly accessible, because it's stored somewhere else, like on tape?
- We can use the
loadendpoint to stream stream the data as Zarr data.
Caveat: Because the data can be accessed from anywhere once it is made available via zarr we need to create an access token:
auth = requests.post(
f"{url}/api/auth/v2/token",
data={"username": "janedoe", "password":getpass("Password: ")}
).json()
"Order" the zarr datasets.¶
With this access token we can generate zarr enpoints to stream the data from anywhere, to do so we simply search for the datasets again:
res = requests.get(
f"{url}/api/databrowser/load/freva",
params=search_params,
headers={
"Authorization": f"Bearer {auth['access_token']}"
},
stream=True
)
This will search for data and for every found entry create a zarr endpoint that can be loaded:
zarr_files = list(res.iter_lines(decode_unicode=True))
zarr_files
['http://localhost:7777/api/freva-data-portal/zarr/dcb608a0-9d77-5045-b656-f21dfb5e9acf.zarr', 'http://localhost:7777/api/freva-data-portal/zarr/f56264e3-d713-5c27-bc4e-c97f15b5fe86.zarr']
Open the zarr datasets¶
Let's load the data with xarray and zarr:
dset = xr.open_dataset(
zarr_files[0],
engine="zarr",
chunks="auto",
storage_options={"headers": {"Authorization": f"Bearer {auth['access_token']}"}}
)
dset
<xarray.Dataset>
Dimensions: (lat: 27, bnds: 2, lon: 43, plev: 19, time: 11)
Coordinates:
* lat (lat) float64 0.9326 2.798 4.663 6.528 ... 43.83 45.7 47.56 49.43
* lon (lon) float64 101.2 103.1 105.0 106.9 ... 174.4 176.2 178.1 180.0
* plev (plev) float64 1e+05 9.25e+04 8.5e+04 7e+04 ... 1e+03 500.0 100.0
* time (time) datetime64[ns] 1979-01-16T12:00:00 ... 1979-11-16
Dimensions without coordinates: bnds
Data variables:
lat_bnds (lat, bnds) float64 dask.array<chunksize=(27, 2), meta=np.ndarray>
lon_bnds (lon, bnds) float64 dask.array<chunksize=(43, 2), meta=np.ndarray>
time_bnds (time, bnds) datetime64[ns] dask.array<chunksize=(11, 2), meta=np.ndarray>
ua (time, plev, lat, lon) float32 dask.array<chunksize=(11, 19, 27, 43), meta=np.ndarray>
Attributes: (12/47)
CDI: Climate Data Interface version 2.0.6 (https://mpim...
source: MPI-ESM1.2-LR (2017): \naerosol: none, prescribed ...
institution: Max Planck Institute for Meteorology, Hamburg 2014...
Conventions: CF-1.7 CMIP-6.2
activity_id: CMIP
branch_method: no parent
... ...
variable_id: ua
variant_label: r2i1p1f1
license: CMIP6 model data produced by MPI-M is licensed und...
cmor_version: 3.5.0
tracking_id: hdl:21.14100/0898c2ad-5382-4d0c-8adb-2ca96387fb54
CDO: Climate Data Operators version 2.0.6 (https://mpim...We do have a xarray dataset, meaning we can just proceed with our analysis:
dset["ua"].mean(dim=("lon", "lat")).plot(x="time", yincrease=False)
<matplotlib.collections.QuadMesh at 0x7f7b7ecefad0>

Creating intake catalogues¶
Intake can conviniently aggregate data. Instead creating individual lists of files we can create an intake catalogue with the zarr end points that helps us to aggregate the data later.
To create an intake catalogue instead of a list of files we simply have to add the catalogue-type:intake search parameter:
import intake
search_params["catalogue-type"] = "intake"
res = requests.get(
f"{url}/api/databrowser/load/freva",
params=search_params,
headers={
"Authorization": f"Bearer {auth['access_token']}"
},
stream=True
)
with NamedTemporaryFile(suffix=".json") as temp_f:
with open(temp_f.name, "w") as stream:
stream.write(res.text)
cat = intake.open_esm_datastore(temp_f.name)
cat.df
| uri | project | product | institute | model | experiment | time_frequency | realm | variable | ensemble | cmor_table | fs_type | grid_label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | http://localhost:7777/api/freva-data-portal/za... | CMIP6 | CMIP | MPI-M | MPI-ESM1-2-LR | amip | mon | atmos | ua | r2i1p1f1 | Amon | posix | gn |
| 1 | http://localhost:7777/api/freva-data-portal/za... | CMIP6 | CMIP | CSIRO-ARCCSS | ACCESS-CM2 | amip | mon | atmos | ua | r1i1p1f1 | Amon | posix | gn |
Using the freva client libray¶
Rest requests can be confusing for many users. The new freva_client library is here to help
from freva_client import authenticate, databrowser
data_query = databrowser(dataset="cmip6-fs", host="localhost:7777", stream_zarr=True)
token = authenticate(username="janedoe", host="localhost:7777")
files = list(data_query)
files
['http://localhost:7777/api/freva-data-portal/zarr/dcb608a0-9d77-5045-b656-f21dfb5e9acf.zarr', 'http://localhost:7777/api/freva-data-portal/zarr/f56264e3-d713-5c27-bc4e-c97f15b5fe86.zarr']
We can also use the freva client library to directly create an intake catalogue:
cat = data_query.intake_catalogue()
cat.df
| uri | project | product | institute | model | experiment | time_frequency | realm | variable | ensemble | cmor_table | fs_type | grid_label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | http://localhost:7777/api/freva-data-portal/za... | CMIP6 | CMIP | MPI-M | MPI-ESM1-2-LR | amip | mon | atmos | ua | r2i1p1f1 | Amon | posix | gn |
| 1 | http://localhost:7777/api/freva-data-portal/za... | CMIP6 | CMIP | CSIRO-ARCCSS | ACCESS-CM2 | amip | mon | atmos | ua | r1i1p1f1 | Amon | posix | gn |
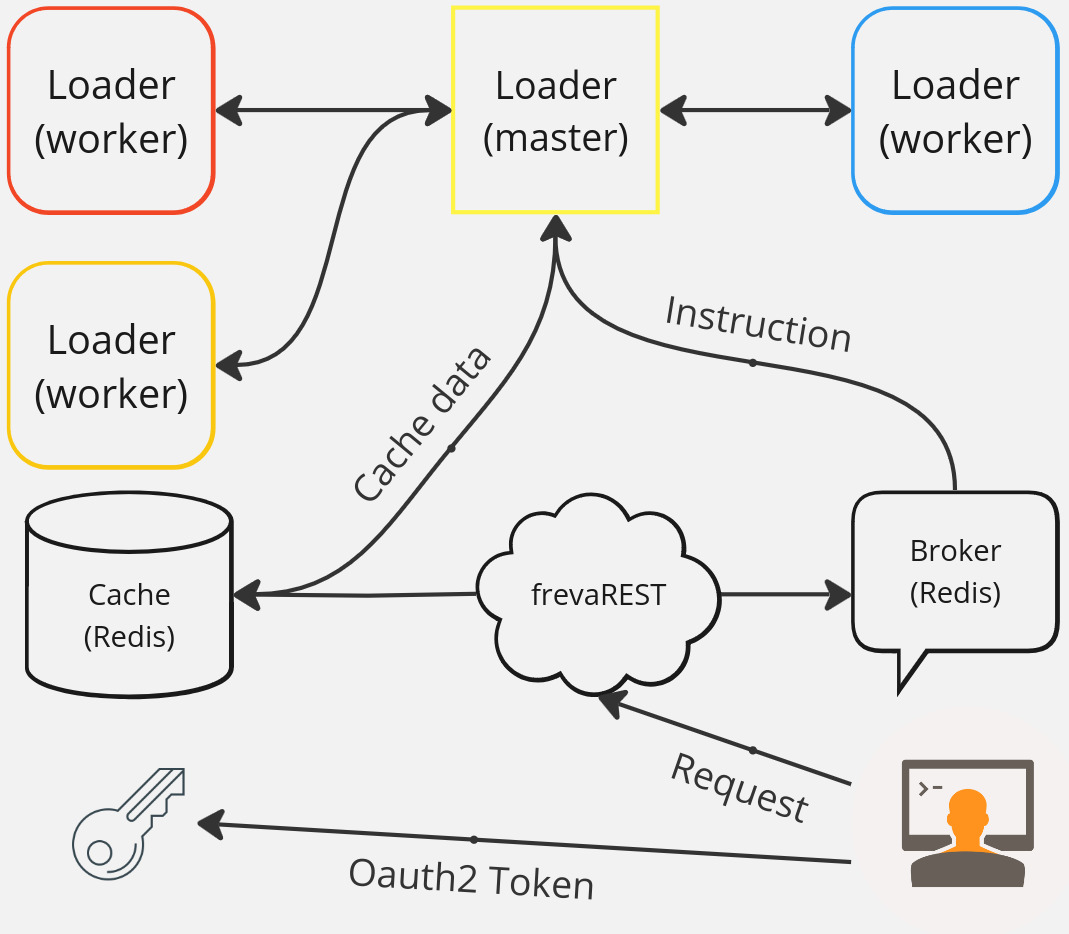
How does it work?¶
What's next?¶
- Add json payload to
loadendpoint that allows the users to pre-precess data. For example select a region by uploading a geojson shape file. - Implement a backend handle to open tape archives